

1. redis란?
redis란 'Remote Dictionary Server'의 약자로, 고성능의 Key-Value 스토어입니다. 이는 메모리 기반의 데이터 구조 서버로서, 데이터베이스, 캐시, 브로커(Pub/Sub모델을 통해 실시간 채팅, 이벤트알림 등) 등의 역할을 수행할 수 있다.빠른 응답 시간과 높은 확장성을 필요로 하는 다양한 서비스에서 널리 사용
2. redis의 collection

redis 는 이렇게 다양한 자료 구조를 지원한다.
3. SingleThread
redis는 싱글스레드를 사용하여 동시성문제가 생기지 않고 작업을 들어온 순서대로 하나씩 처리한다. 또 Redis 4.0부터는 'Redis Module'을 지원하여, 사용자가 별도의 스레드를 생성해서 사용할 수 있게 되었고, Redis 6.0부터는 'IO Threading' 기능을 도입하여, 네트워크 I/O 작업을 병렬로 처리할 수 있게 되었습니다.
이런 기능을 통해 Redis는 싱글 스레드 모델의 장점을 최대한 살리면서,멀티 스레드의 이점도 가져가고 있습니다.
4. replication, clutering
Redis의 복제(Replication)와 클러스터링(Clustering)은 두 가지 중요한 기능으로, 데이터의 안전성과 확장성을 높이는 데 사용된다.
1.
복제(Replication): Redis의 복제 기능은 한 개의 Redis 서버(주로 '마스터'라 불림)의 데이터를 하나 이상의 Redis 서버('슬레이브'라 불림)에 복사하는 기능입니다. 슬레이브는 마스터의 데이터를 실시간으로 복제받아, 마스터에 문제가 발생했을 때 데이터의 손실을 방지하거나, 읽기 요청의 부하를 분산하는 데 사용됩니다. 복제는 Redis 설정에서 간단하게 활성화할 수 있으며, 네트워크 분할이나 장애 상황에서도 잘 동작합니다.
2.
클러스터링(Clustering): Redis 클러스터는 여러 개의 Redis 서버를 하나의 논리적인 작업 단위로 묶는 기능입니다. 이를 통해 Redis의 데이터와 처리능력을 수평적으로 확장할 수 있습니다. 클러스터는 데이터를 여러 노드에 분할(Sharding)하여 저장하므로, 하나의 노드에서 처리할 수 있는 데이터나 요청의 양을 넘어서는 큰 규모의 데이터를 처리할 수 있습니다. 또한, Redis 클러스터는 자동 복구 기능을 제공하여, 노드 장애가 발생해도 클러스터가 계속 작동하도록 합니다.
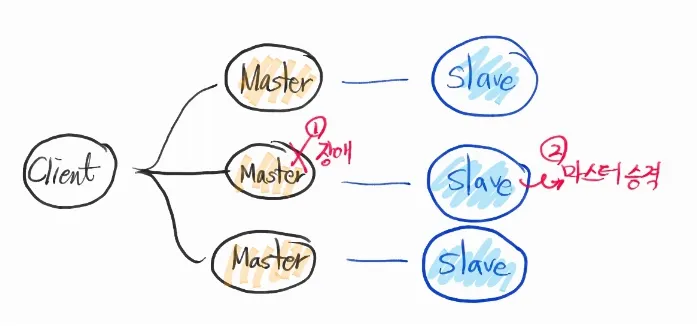
이 두 가지 기능은 서로 독립적으로 사용할 수 있지만, 많은 경우에 함께 사용하여, 대규모의 데이터를 안정적으로 처리하고, 높은 가용성 을 보장하는 데 사용됩니다. 예를 들어, 클러스터의 각 노드는 복제 기능을 사용하여 자신의 데이터를 다른 노드에 복제함으로써, 노드 장애에 대비할 수 있습니다.






