

SHOW ME THE CACHE !!! 캐시에 대해서 알아봅니다.
1. 노답 4형제
쿠키 vs 세션 vs 토큰 vs 캐시
각자 역할이 있지만 어떻게 조합해서 사용하는지 정답이 정해져있지 않은 노답 사형제 입니다.
규모가 클수록 4개 모두 사용하며, 규모가 작을수록 하나씩 덜어낼 수 있습니다.

끈질긴 놈 vs 꼼꼼한 놈 vs 얍삽한 놈 vs 재빠른 놈
쿠키

끈질긴 놈
유저 옆에 붙어있는 끈질긴 놈
사용자에 의해 조작되어도 크게 문제되지 않아서 브라우저에 저장해두는 정보
세션

꼼꼼한 놈
유저들 이름 다 적어놓는 꼼꼼한 놈
조작되면 안되어서 서버에 저장하는 인증에 대한 정보
토큰

얍삽한 놈
유저들 손등에 도장 찍어놓는 얍삽한 놈
조작되면 안되어서 서버의 암호키(도장)로 암호화 해서 사용자가 저장해두는 정보
 귀찮다고 얍삽하게 도장만 찍다가 도장관리하는게 더 복잡해진건 안비밀 (ATK, RTK 등…)
귀찮다고 얍삽하게 도장만 찍다가 도장관리하는게 더 복잡해진건 안비밀 (ATK, RTK 등…)캐시

재빠른 놈
유저들이 또 달라고 할까봐 미리 들고있는 재빠른 놈
한번 RDB 조회한 데이터를 저장해 놨다가 필요할 때 꺼내서 재사용하는 정보
쿠키(Cookie) | 세션(Session) | 토큰(Token) | 캐시(Cache) | |
저장 위치 | 클라이언트(=접속자 PC) | 서버 | 클라이언트 | 서버 |
저장 형식 | text | Object (with Session ID) | JWT Object | Map<Key, Value>
(문자열, List, Set, Sorted Set 등 다양한 Value 타입을 지원) |
저장 데이터 | 접속자의 설정과 과거 이용내역에 대한 일부 데이터 | 로그인 인증 데이터 | 로그인 인증 데이터 | 자주 조회하는 데이터 |
만료 시점 | 쿠키 저장시 설정(브라우저가 종료되도, 만료시점이 지나지 않으면 자동삭제되지 않음) | 브라우저 종료시 삭제(기간 지정 가능) | 토큰 생성시 수명 지정
(Access Token, Refresh Token 각자 다르게 기간 지정 가능) | 캐시 데이터 생성시 수명 지정(TTL=TimeToLive) |
사용하는 자원(리소스) | 클라이언트 리소스 | 서버 리소스 | 클라이언트 리소스 | 서버 리소스 |
용량 제한 | 총 300개하나의 도메인 당 20개하나의 쿠키 당 4KB(=4096byte) | 서버의 메모리 용량만큼 제한 | - | 서버 또는 캐시 저장소의 메모리 용량만큼 제한 |
데이터 크기 | | | (헤더,페이로드,서명) | |
서버 부담 | | (서버 저장) | | |
속도 | | | | |
보안 | | | (다중 요청, 탈취) | |
확장성 | | (세션 불일치) | | |
토큰의 다중요청, 탈취 문제 해결방법
인증토큰(ATK) 자체의 수명을 아주 짧게 주고, 인증토큰(ATK)을 자주 갱신하도록 한다.
그리고 인증토큰(ATK) 갱신을 위해 수명이 좀더 긴 갱신토큰(RTK)을 함께 발급해주어 갱신요청시 갱신토큰(RTK)이 유효한지 확인 후 재발급해준다.
다중 서버 구조에서의 Session 불일치 문제 해결방법
이런 문제를 해결하기 위해 유저의 요청이 무조건 세션을 생성한 서버로 향하도록 하는 Sticky Session, 여러 웹서버가 모두 동일한 세션 정보를 가지고 있는 Session Clustering 방식이 있지만, 세션 정보를 관리하는 서버를 아예 별개로 두는 Session Storage 방식이 가장 많이 쓰인다고 한다.
2. 어서와이제이션
인증 vs 인가(어서와이제이션)
인가란 이미 인증된 사용자에 대해 환영하며 권한을 체크해주는 기능이라 “어서와~이제이션”이라고 부른다고함(by.얄코) = Authorization

인증 (Authentication)
인증은 쉽게 말하자면, 로그인 이다. 클라이언트가 자기자신이라고 주장하고 있는 사용자가 맞는지를 검증하는 과정이다. 예를 들어 로그인 화면에서 내가 유저 아이디를 USER1 로 입력하고 패스워드를 입력해 제출하면, 서버에서는 내가 진짜로 USER1 이라는 유저가 맞는지 확인한다.
인가 (Authorization)
인가는 인증 작업 이후에 행해지는 작업으로, 인증된 사용자에 대한 자원에 대한 접근 확인 절차를 의미한다.
여기에 일반 유저인 USER1과 USER2가 있다. 일반 유저인 USER1 은 글 작성, 조회, 수정, 삭제 등 일반적인 작업에 대한 권한이 부여되어 있다. 하지만 USER1 은 USER2가 작성한 글을 수정하거나 제거할 수는 없다. 타인의 리소스에 대해서는 인가되어 있지 않기 때문이다. 또한 USER1과 USER2 는 모두 관리자 페이지에 접속할 수 없다. 일반 유저는 관리자 페이지에 대해 인가되어 있지 않기 때문이다.
HTTP의 비상태성(Stateless)
HTTP는 비상태성이라는 특성을 갖는다. 서버는 클라이언트의 상태를 저장하지 않으며, 따라서 이전 요청과 다음 요청의 맥락이 이어지지 않는다. HTTP는 바로 직전에 발생한 통신을 기억하지 못한다. 따라서 HTTP 단독으로는 요청한 클라이언트가 이전에 이미 인증과정을 거쳤는지 알 방법이 없다.
이런 HTTP 환경에서 서버는 어떤 방식으로 사용자를 인가할까? 웹 어플리케이션에서는 이 문제를 세션 또는 토큰을 사용하여 문제를 해결한다.




3. 어쩔 레디스, 저쩔 레디스
레디스 : 인메모리 저장소 (스토리지)
MySQL : 디스크 저장소
Redis : 인메모리 저장소
어쩔 레디스(인증), 저쩔 레디스(캐시)
세션, 토큰을 저장하여 문제를 해결할때 Redis 저장소를 주로 사용한다.
뿐만 아니라 Redis 를 통해 캐싱(조회 최적화)도 할 수 있다.

레디스는 다양하게 사용할 수 있습니다.
어쩔 레디스 (인증)
•
세션 인증정보를 Redis 에 저장하기
◦
서버에 접속중인 사용자들의 세션정보를 Redis 에 저장 해둔다.
◦
서버 재시작시 사용자들이 모두 로그아웃처리 된다.
◦
하나의 세션을 하나의 요청만 받도록 할 수 있다. (즉, 한 계정으로 한 기기에서만 접속하게 제한 가능함)
•
토큰 인증정보를 Redis 에 저장하기
◦
화이트 리스트 방법과 블랙 리스트 방법이 있다.
◦
화이트 리스트 : 세션정보처럼 로그인한 유저들의 토큰정보를 만료시간까지 저장한다.
◦
블랙 리스트 : 로그아웃한 유저들의 토큰정보를 만료시간까지 저장한다. (리프래쉬 토큰)
◦
하나의 토큰으로 여러번 요청할 수 있다. (즉, 한 계정으로 여러 기기에서 접속 가능함)

저쩔 레디스(캐시)
•
RDB의 데이터를 Redis 에 저장하기
◦
RDB에서는 연산을 처리할 때마다 디스크 I/O가 발생하기 때문에 느리다. (병목현상 발생)
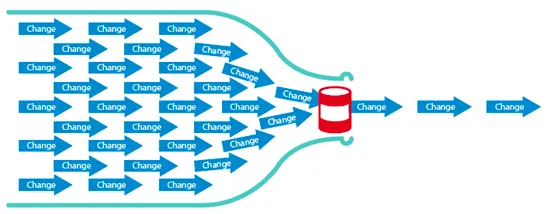
병목현상 (Bottle Neck)
◦
RDB는 데이터 정합성의 보장을 위해 주로 Scale Up 방식으로 성능 향상을 하게 된다. Scale Up은 성능 확장에 한계가 있기 때문에 장애가 발생하지 않도록 부하를 최대한 분산시켜주는 것이 중요하다.
◦
RDB의 부하를 앞에서 막아주기 위해 캐시 저장소를 사용하며 이때 Redis 를 많이 사용한다.
◦
Redis 는 수평확장이 가능하고, 복제본 생성이 간편하여 빠르게 복구하거나, 읽기/쓰기 부하를 분산시킬 수 있다.

대용량 처리에서 Redis 성능 개선하기
Redis 는 데이터의 정합성을 보장하기 위해 싱글 스레드로 운영되는데 이로인해서 인메모리 DB임에도 성능이 잘 나오지 않을 수 있습니다. 이때 요청을 분류하여 여러대의 Redis 서버를 구성할 수 있습니다.
하나의 Spring 앱에서 2개 이상의 DB(DataSource)를 연결하면 Bean 중복에러가 발생한다. 이를 해결하는 방법으로 Bean 이름을 개별지정해주는 방법이 있다.
•
@Primary : 동일한 타입의 빈이 여러 개가 존재하는 경우, 해당 어노테이션이 붙은 빈을 우선적으로 주입
•
@Qualifier : 동일한 타입의 빈이 여러 개가 존재하는 경우, 지정된 조건과 일치하는 빈을 주입
•
@Resource : @Autowired 와 달리 명시한 빈의 아이디와 일치하는 빈을 먼저 검색하여 주입

4. 쇼미더 캐시
•
캐시는 파레토의 법칙에 따른 최적화 기술 입니다.
파레토 법칙

20% 사용자가 80%의 사용량을 차지한다.
즉, 20% 중복된 요청이 전체 요청량의 80%!!
캐시에 모든 데이터를 저장할 필요 없이 "파레토 법칙"에 따라 일부만 저장해도 대부분의 데이터를 커버할 수 있습니다. (헤비 유저)
파레토 법칙- 8:2 법칙
서비스에 빗대어 표현하자면 80%의 활동을 20%의 유저가 하기 때문에 20%의 데이터만 캐시 해도 서비스 대부분의 데이터를 커버할 수 있게 됩니다.
상황에 맞는 캐싱 전략을 사용한다면 DB의 부하를 줄일 수 있고 응답에 대한 지연시간 감소와 처리량 증가로 인해 서비스 성능을 향상시킬 수 있습니다.
캐시(Cache) 란?
캐시(Cache)는 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 저장소입니다.

속도 향상을 위해 캐시를 사용하며, 다음과 같은 상황에서 캐시를 주로 사용합니다.
•
원본 데이터보다 빠르게 접근 가능할 때
•
같은 데이터에 반복적으로 접근할 때
•
자주 변하지 않은 데이터를 주로 사용할 때 (변할때 Evict(삭제) 시켜주거나 Put(업데이트)해줘야 한다.)
레디스(Redis)는 단순한 구조와 in-memory저장소로 인한 빠른 성능 때문에 캐시에 주로 쓰입니다.
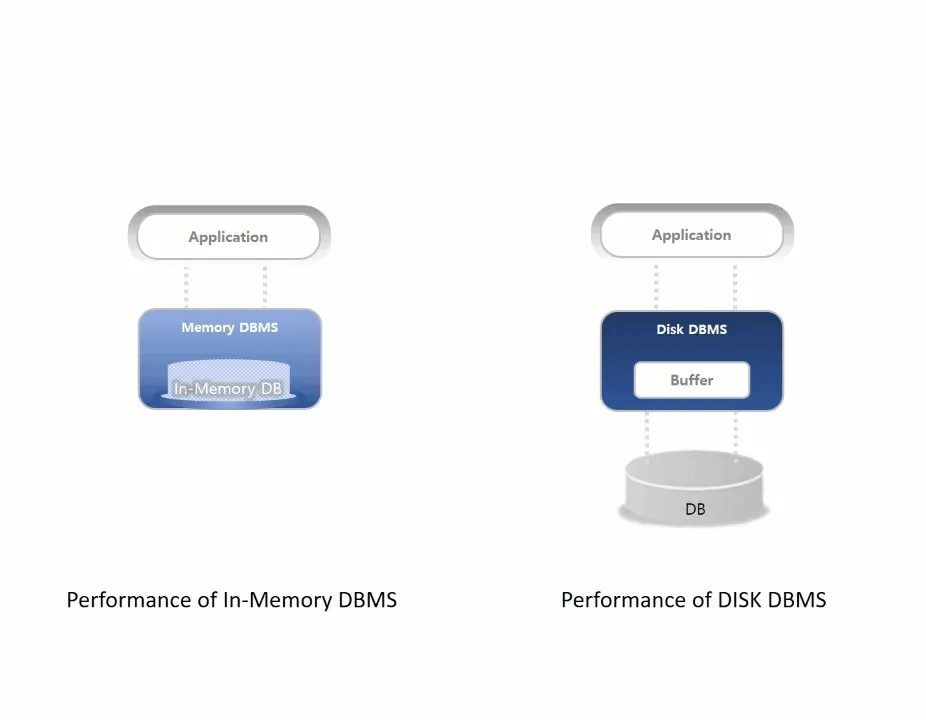
AWS 에서 설명하는 캐싱
캐시의 데이터는 일반적으로 RAM(Random Access Memory)과 같이 빠르게 액세스할 수 있는 하드웨어에 저장되며, 소프트웨어 구성 요소와 함께 사용될 수도 있습니다. 캐시의 주요 목적은 더 느린 기본 스토리지 계층에 액세스해야 하는 필요를 줄임으로써 데이터 검색 성능을 높이는 것입니다.
속도를 위해 용량을 절충하는 캐시는 일반적으로 데이터의 하위 집합을 일시적으로 저장합니다. 보통 완전하고 영구적인 데이터가 있는 데이터베이스와는 대조적입니다.
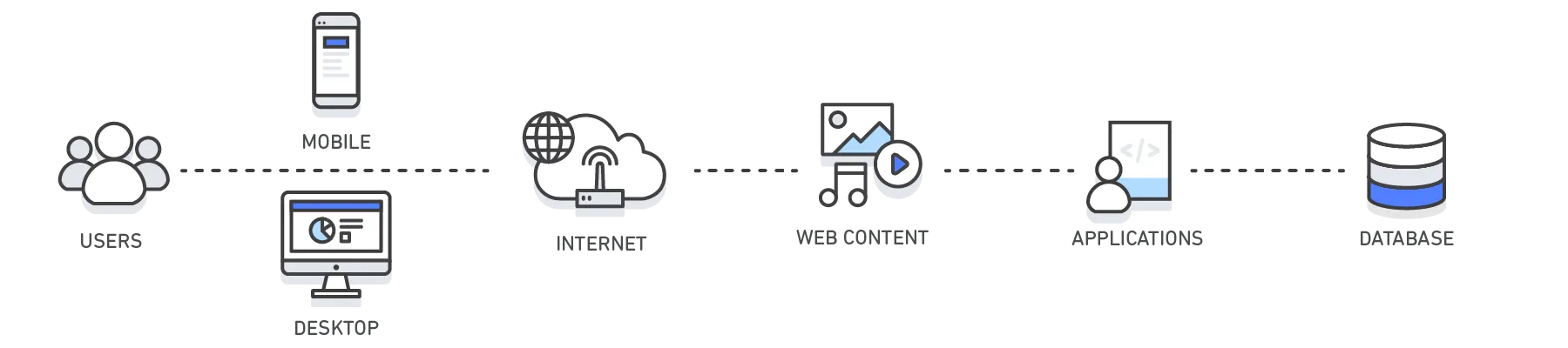
계층 | 클라이언트 측 | DNS | 웹 | 앱 | 데이터베이스 |
사용 사례 | 웹 사이트에서 웹 콘텐츠를 검색하는 속도 가속화(브라우저 또는 디바이스) | 도메인과 IP 간 확인 | 웹 또는 앱 서버에서 웹 콘텐츠를 검색하는 속도를 높입니다. 웹 세션 관리(서버 측) | 애플리케이션 성능 및 데이터 액세스 가속화 | 데이터베이스 쿼리 요청과 관련한 지연 시간 단축 |
기술 | HTTP 캐시 헤더, 브라우저 | DNS 서버 | HTTP 캐시 헤더, CDN, 역방향 프록시, 웹 액셀러레이터, 키-값 스토어 | 키-값 데이터 스토어, 로컬 캐시 | 데이터베이스 버퍼, 키-값 데이터 스토어 |
솔루션 | 브라우저별 |
캐싱 방법
로컬 캐싱 vs 글로벌 캐싱
로컬 캐싱 (ex. ehCache)
•
장점 : 연동 간편하다, 빠르다
•
단점 : 서버간 공유가 불가능하다.
•
서버 내부 저장소에 캐시 데이터를 저장하는 것
•
속도는 빠르지만 서버 간의 데이터 공유가 안된다는 단점이 있다.
•
이외에도 서버 별 중복된 캐시 데이터로 인한 서버 자원 낭비, 힙 영역에 저장된 데이터로 발생하는 GC에 대한 문제 등을 고려해야 한다.
글로벌 캐싱 (ex. Redis)
•
장점 : 서버간 공유가 가능하다.
•
단점 : 로컬 캐싱에 비해서 속도가 느리가 (네트워크 비용이 있기때문에), GC자유롭긴, 연동 로컬캐시보단 불편
•
서버 내부 저장소가 아닌 별도의 캐시 서버를 두어 각 서버에서 캐시 서버를 참조하는 것
•
캐시 데이터를 얻으려 할 때마다 캐시 서버로의 네트워크 트래픽이 발생하기 때문에 로컬 캐싱보다 속도는 느리다.
•
서버 간에 캐시 데이터를 쉽게 공유할 수 있기 때문에 위에서 언급한 로컬 캐싱의 문제를 해결할 수 있다.
•
따라서, 글로벌 캐싱 전략을 선택하고 현재 세션 스토리지로 사용하고 있는 Redis를 캐시 저장소로도 활용할 수 있다.
캐싱 전략
캐시로 사용할 때 어떻게 배치하는지가 시스템 성능에 큰 영향을 끼치는데 이를 캐싱 전략(Caching Strtegies)이라고 합니다.
Look-Aside
Look-Aside는 데이터를 찾을 때 우선 캐시에서 데이터를 찾고 데이터가 있다면 캐시에서 데이터를 가지고 오는 전략입니다.
만약 캐시에 데이터가 없어 Cache Miss가 발생한다면 앱은 DB에서 데이터를 가져온 뒤 캐시에 넣어주는 작업을 합니다.
캐시에 찾는 데이터가 없을 때 DB에 직접 조회해서 입력되기 때문에 Lazy Loading이라고 합니다.

이 구조는 캐시가 다운되더라도 DB에서 데이터를 가지고 올 수 있습니다.
만약 레디스가 다운되거나 DB에만 새로운 데이터가 있다면 Cache Miss로 인해서 많은 프로세스가 DB에 접근하기 때문에 DB에 많은 부하가 생길 수 있습니다.

이런 경우 DB에서 캐시로 데이터를 미리 넣어주는 작업을 하기도 하는데 이를 Cache Warming이라고 합니다.
Read Through
Read Through는 캐시에서만 데이터를 읽어오는 전략입니다.
Cache miss가 발생한다면 캐시는 DB에서 데이터를 검색하고 캐시에 자체 업데이트한 뒤 앱에 데이터를 보내줍니다.

Read Through
Write Through
Write Through는 데이터를 저장할 때 먼저 캐시에 저장한 다음 DB에 저장하는 방식입니다.

Write Through
캐시는 항상 최신 정보를 가지고 있지만 저장할 때마다 두 단계 스텝을 거쳐야 하기 때문에 상대적으로 느립니다.
또한 저장하는 데이터가 재사용되지 않을 수도 있는데 무조건 캐시에 넣어버리기 때문에 리소스 낭비가 발생할 수 있습니다.
이를 방지하기 위해 캐시에 expire time을 설정하기도 합니다.
Expire time?
Write Back (a.k.a Write Behind)
Write Back은 먼저 캐시에 데이터를 저장했다가 특정 시점마다 DB에 저장하는 방식입니다.

Write Back
캐시에 데이터를 모았다가 한 번에 DB에 저장하기 때문에 DB 쓰기 비용을 절약할 수 있지만 데이터를 옮기기 전에 캐시 장애가 발생하면 데이터 유실이 발생할 수 있습니다.
Write Around
Write Around는 모든 데이터는 DB에 저장되고 읽은 데이터만 캐시에 저장되는 방식입니다.

Cache miss가 발생하는 경우에만 캐시에 데이터를 저장하기 때문에 캐시와 DB 내의 데이터가 다를 수 있습니다.
Write Around는 주로 Look aside, Read through와 결합해서 사용됩니다.


Refactoring: 캐싱 적용
스프링 프레임워크에서는 캐시 추상화를 지원하기 때문에 별도의 캐시 로직을 작성할 필요없이 어플리케이션에 캐싱 기능을 쉽게 적용할 수 있다. 그러나 캐시 저장소를 제공하지는 않으므로 직접 설정을 해주어야 한다. 그리고 CacheManager라는 인터페이스를 활용하여 직접 지정한 저장소의 캐시를 관리하는데 사용되는 캐시 공급자를 구현해야 한다.
@EnableCaching 어노테이션 적용

먼저 @EnableCaching 어노테이션으로 캐싱 기능을 활성화한다. 위의 그림처럼 캐싱 기능이 활성화되면 CacheManager 타입의 빈을 호출하여 캐시 어노테이션이 붙은 컴포넌트들을 스프링이 관리하기 시작한다. @Transaction 처럼 Spring AOP를 통해 @Cacheable 이 설정된 메서드가 호출될 때마다 지정된 인수에 대해 호출 여부를 확인한다. 메서드가 호출된 적이 없었다면 메서드를 호출하는 과정에서 결과를 캐시한 후 사용자에게 반환한다. 반대로 이미 호출된 적이 있었다면 이전에 캐시된 데이터를 반환하게 된다. (위의 그림은 스프링이 제공하는 기본 캐시를 사용할 때의 그림이다. 만약 외부 저장소를 사용한다면 ConcurrentHashMap 대신 외부 저장소 서버로 대체해서 생각하면 된다.)
@EnableCaching
@SpringBootApplication
public class SnsServerApplication {
publicstaticvoidmain(String[] args) {
SpringApplication.run(SnsServerApplication.class, args);
}
}
Less
복사
RedisCacheManager 등록
우리는 Redis를 캐시 저장소로 사용하기로 했으므로 RedisCacheManager 를 빈으로 등록하여 기본 CacheManager 를 대체한다.
@Configuration
public class CacheConfiguration {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration defaultConfig = RedisCacheConfiguration.defaultCacheConfig()
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
// 리소스 유형에 따라 만료 시간을 다르게 지정
Map<String, RedisCacheConfiguration> redisCacheConfigMap =new HashMap<>();
redisCacheConfigMap.put(CacheNames.POST, defaultConfig.entryTtl(Duration.ofHours(1)));
redisCacheConfigMap.put(CacheNames.FEED, defaultConfig.entryTtl(Duration.ofSeconds(5L)));
RedisCacheManager redisCacheManager = RedisCacheManager.builder(connectionFactory)
.withInitialCacheConfigurations(redisCacheConfigMap)
.build();
return redisCacheManager;
}
}
Java
복사
RedisCacheConfiguration 오브젝트로 RedisCacheManager 에 관련 옵션을 설정할 수 있으며 각 옵션의 의미는 다음과 같다.
•
serializeValuesWith : 캐시 Value를 직렬화-역직렬화 하는데 사용하는 Pair 지정
◦
Value는 다양한 자료구조가 올 수 있기 때문에 GenericJackson2JsonRedisSerializer 를 사용
◦
Key Serializer 기본 값은 StringRedisSerializer 로 지정되어 있어 serializeKeysWith 생략
•
withInitialCacheConfigurations : 여러 개의 CacheConfiguration 을 설정할 때 사용
•
entryTtl : 캐시의 만료 시간을 설정
현재 진행하는 SNS 프로젝트에서는 캐싱을 적용할 대상으로 게시물과 피드로 선정했다. 게시물은 한 번 작성하면 변경이 거의 일어나지 않지만 게시물들이 모여 있는 피드는 각각의 게시물의 생성, 변경, 삭제로 인해 비교적 변경이 자주 발생한다. 그래서 리소스의 유형에 따라 CacheName 을 정의하고 CacheName 마다 캐시의 만료시간을 다르게 설정했다.
캐시 어노테이션 적용
스프링의 캐시 추상화에서 제공하는 다양한 캐시 어노테이션으로 메소드에 대한 캐시 제어를 쉽게 할 수 있다. 나의 프로젝트에서 주로 사용한 캐시 어노테이션은 다음과 같다.
@Cacheable
@Override
@Cacheable(cacheNames = CacheNames.FEED, key = "#userId")
public List<Post> getPostsByUser(String userId) {
List<Post> posts = postMapper.getPostsByUserId(userId);
return posts;
}
Java
복사
@Cacheable 은 해당 메소드의 리턴값을 캐시에 저장한다. @Cacheable 은 주로 읽기 작업이 일어나는 메소드에 적용되며 메소드가 호출될 때마다 캐시 저장소에 저장된 캐시가 있는지 확인하고, 있다면 메소드를 실행하지 않고 캐시 데이터를 반환한다.
•
cacheNames: 캐시 이름
•
key: 캐시 이름이 같을 때, 사용되는 구분 값
◦
Redis에 실제로 저장될 때는 "cacheNames::key" 형식으로 저장된다.
@CacheEvict
@Override
@CacheEvict(cacheNames = CacheNames.FEED, key = "#user.userId")
public void uploadPost(User user, String content, List<MultipartFile> images) {
PostUploadInfo postUploadInfo =new PostUploadInfo(user.getUserId(), content);
postMapper.insertPost(postUploadInfo);
int postId = postMapper.getLatestPostId(user.getUserId());
if (!images.isEmpty()) {
if (images.size() == 1) {
FileInfo fileInfo = fileService.uploadFile(images.get(0), user.getUserId());
fileService.uploadImage(postId, fileInfo);
}else {
List<FileInfo> fileInfos = fileService.uploadFiles(images, user.getUserId());
fileService.uploadImages(postId, fileInfos);
}
}
}
Java
복사
@CacheEvict 는 지정된 키에 해당하는 캐시를 삭제한다. 캐싱 대상 리소스에 변경 작업을 하는 메소드라면 @CacheEvict 어노테이션을 적용해주는 것이 좋다. 만약 @CacheEvict 을 적용하지 않고 데이터를 수정한다면 데이터베이스의 데이터는 수정되지만 캐시 저장소의 데이터는 수정 전의 상태로 남아있게 된다. 이때 캐시가 만료되기 전에 수정된 데이터를 조회하면 데이터 불일치가 발생하므로 데이터 변경이 일어난다면 기존 캐시 데이터를 제거해야 한다.
@Caching
@Override
@Caching(evict = {@CacheEvict(cacheNames = CacheNames.POST, key = "#postId"),
@CacheEvict(cacheNames = CacheNames.FEED, key = "#user.userId")})
public void updatePost(User user,int postId, String content)throws AccessException{
boolean isAuthorizedOnPost = postMapper.isAuthorizedOnPost(user.getUserId(), postId);
if (isAuthorizedOnPost) {
postMapper.updatePost(postId, content);
}else {
thrownew AccessException("해당 게시물의 수정 권한이 없습니다.");
}
}
Java
복사
@Caching 은 여러 캐싱 작업을 한 번에 적용시키기 위한 어노테이션이다. 주로 조건식이나 표현식이 다른 경우 혹은 여러 종류의 캐시에 함께 작업을 지정해야 하는 경우 사용하게 된다.
After Refactoring
Postman으로 사용자의 피드를 가져오는 기능을 테스트를 해보았다.(초기화 설정을 하는 시간을 배제하기 위해 해당 기능을 테스트 하기 전에 충분히 warm up을 하였다.) 캐싱 적용 전에는 응답 시간이 110ms 걸리던 것이

캐싱 적용 후에는 42ms로 줄어든 것을 볼 수 있다.

Redis에서도 조회해보면 소스코드에서 지정한 캐시 이름과 키로 캐시 데이터가 저장되어 있는 것을 볼 수 있다.
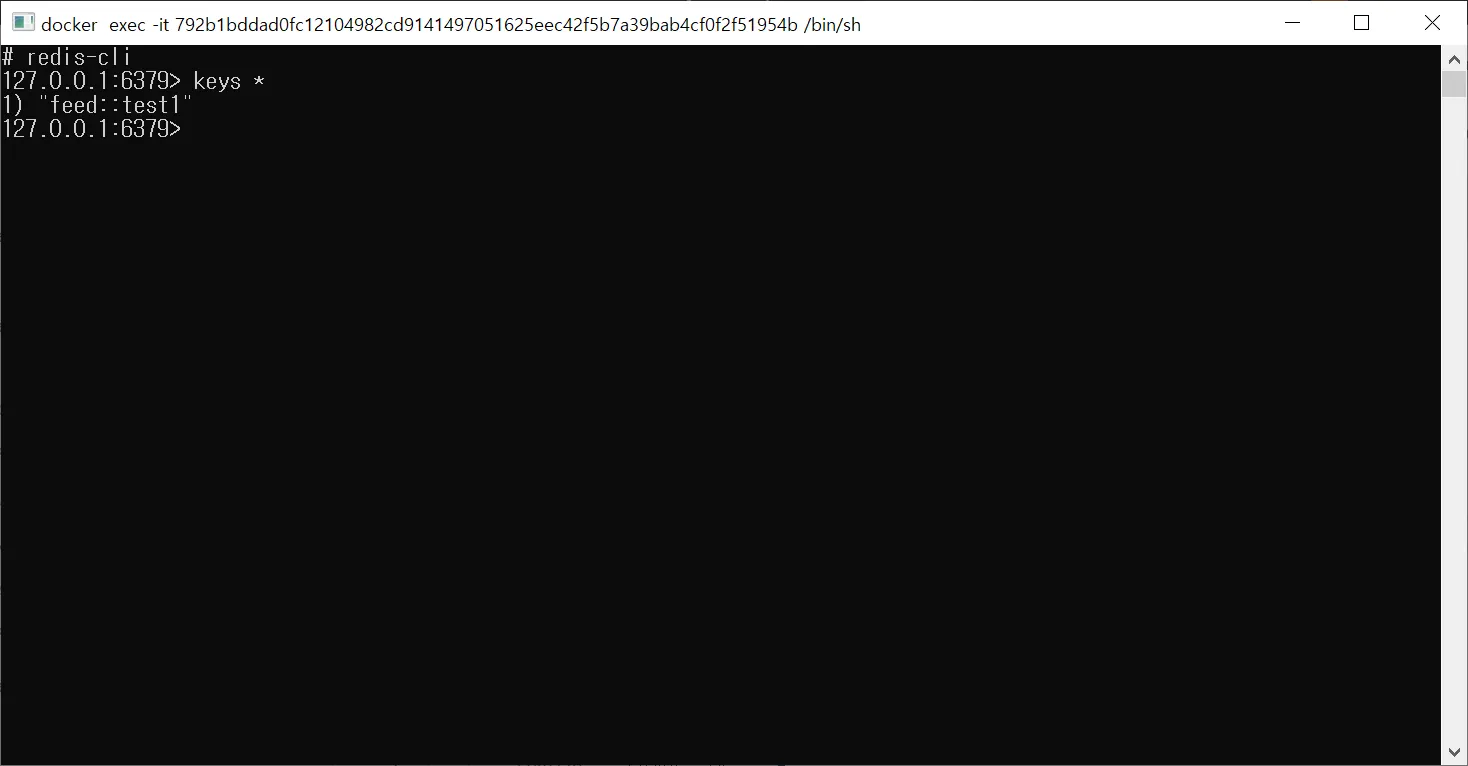

Q. 엔티티 매니저의 1차 캐시랑 같은 의미의 캐시인가요?
A. 네 같은 의미의 캐시이며 2차캐시에 해당하는것이 로컬캐시 또는 글로벌 캐시 입니다.
