
한정된 네트워크 자원을 효율적으로 활용하기 위해 특정한 정렬 기준에 따라 데이터를 분할하여 가져오는 것

오프셋 기반 페이지네이션 (Offset-based Pagination)
•
DB의 offset쿼리를 사용하여 ‘페이지’ 단위로 구분하여 요청/응답
커서 기반 페이지네이션 (Cursor-based Pagination)
•
Cursor 개념을 사용하여 사용자에게 응답해준 마지막 데이터 기준으로 다음 n개 요청/응답
우리 서비스에 보다 적합한 방식은 무엇일까?
결론부터 말하면 우리팀은 커서 기반 페이지네이션 (Cursor-based Pagination) 을 도입하기로 결정했다.
우리팀이 커서 기반 페이지네이션을 도입한 이유
첫번째. 우리팀 주요 서비스는 실시간 채팅 기반 플랫폼이다.
우리팀 주요 서비스는 실시간 채팅 기반 플랫폼이다. 실시간 채팅의 경우는 잦은 수정, 생성, 삭제가 반복되기 때문에 오프셋 기반으로 할 경우 중복 데이터처리가 발생할 우려가 있다.
채팅의 경우 잦은 수정, 생성, 삭제가 반복되기 때문에 오프셋 기반으로 할 경우 중복 데이터처리 발생 우려가 있다.
예를 들어, 오프셋 첫번째 페이지에 1번 ~ 20번 채팅 목록 20개를 띄어주었다.
그 사이 사용자가 새로운 채팅을 5개를 추가하였다면 다음 두번째 페이지를 요청할 때 20번째 ~ 40번째 중 처음 5개는 이전 첫번째 데이터와 중복되는 문제가 발생한다.
두번째. OFFSET 쿼리의 퍼포먼스 이슈
극단적으로 페이지의 수가 10억번의 페이지에 있는 값을 찾고 싶다면 OFFSET에 매우 큰 숫자가 들어가게 되는 문제가 발생한다.
즉, 정렬기준에 대해 해당 row가 몇 번째 순서인지 알지 못하므로 OFFSET 값을 지정하여 쿼리를 한다고 했을 때 지정된 OFFSET까지 모두 만들어 놓은 후 지정된 갯수를 순회하여 비효율적인 문제가 발생한다.
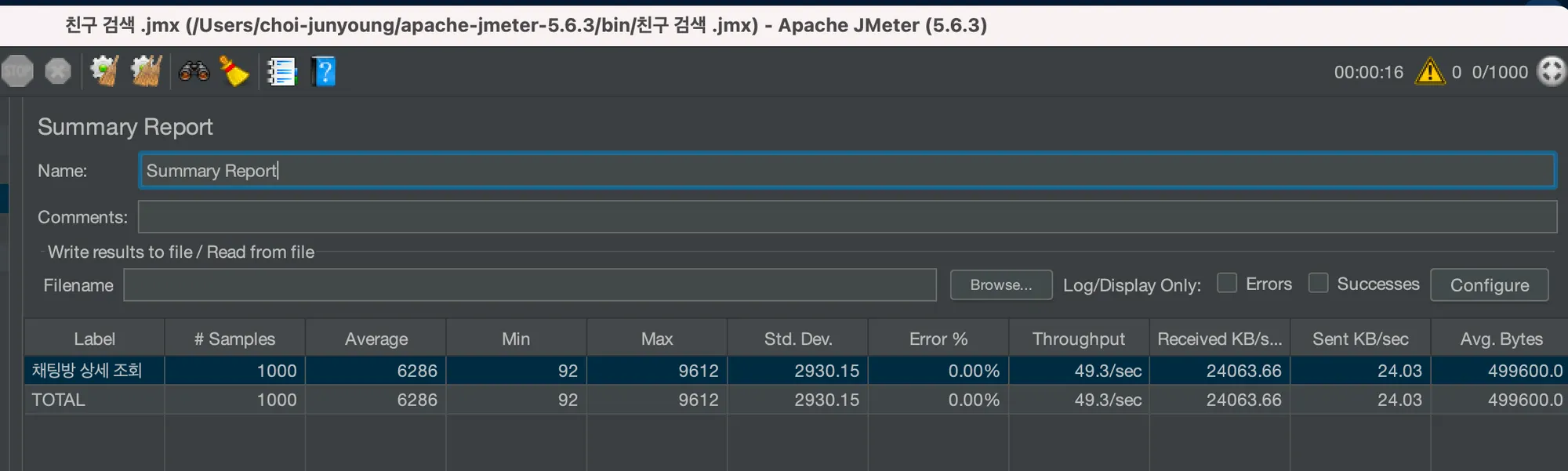
성능 체크
동시 사용자 1000명
조회 데이터 (채팅의 개수) 2000개
평균 속도 6280ms
TPS(초당 데이터 처리량) 49.3/sec
커서 기반 페이징 처리 도입
•
QueryDSL 을 활용하여 Page 처리
@Transactional(readOnly = true)
public ChatRoomPaginationDetailGetRes getPaginationDetailChatRoom(Long chatRoomId,
Long lastChatId,
User user) {
isChatRoomMember(chatRoomId, user.getId());
ChatRoom chatRoom = findById(chatRoomId);
Slice<ChatRes> chatResList =
chatRepository.findChatsByChatRoomId(chatRoomId, lastChatId, LIMIT_SIZE); // 10개
return ChatRoomPaginationDetailGetRes.builder()
.title(chatRoom.getTitle())
.chatResList(chatResList)
.build();
}
Java
복사
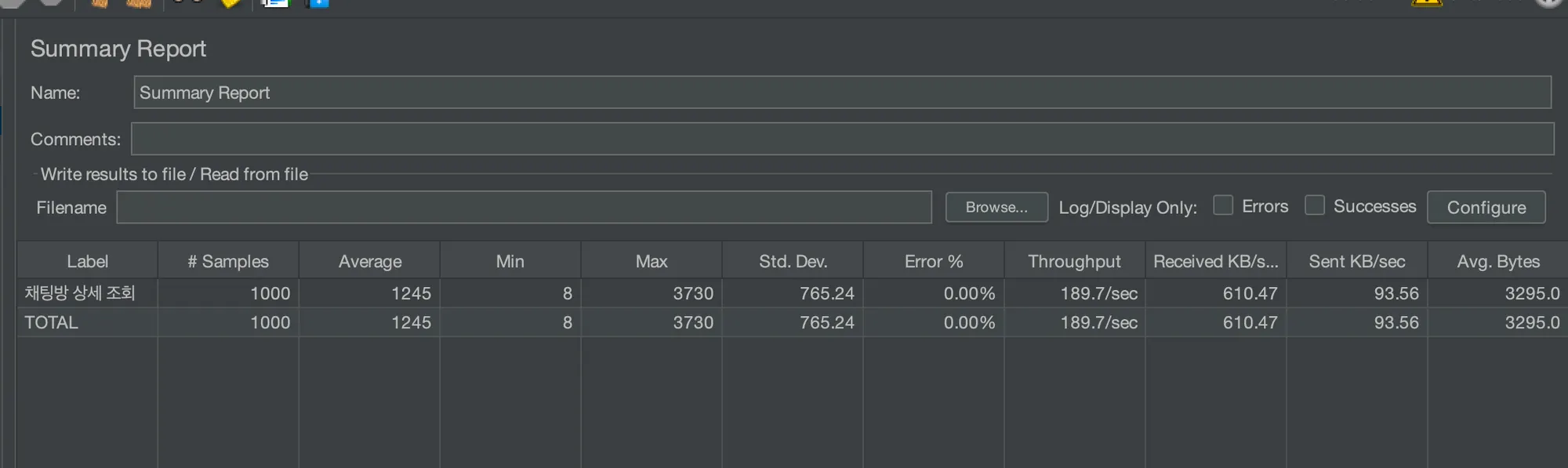
평균 속도 1245ms
TPS(초당 데이터 처리량) 189.7/sec
결과
평균 속도 → 약 500% 성능 개선
TPS → 약 380% 성능 개선
커서 기반 페이징 처리 내부 로직 개선
Collections.reverse()
Front에 역순으로 데이터를 반환하는 방식 보다는
Front에서 반환받은 데이터를 역순으로 순회하는 방식으로 성능 개선
[Collections Class]
-----------------------------------------------------------------------------
public class Collections {
public static void reverse(List<?> list) {
int size = list.size();
if (size < REVERSE_THRESHOLD || list instanceof RandomAccess) {
for (int i=0, mid=size>>1, j=size-1; i<mid; i++, j--)
swap(list, i, j);
} else {
// instead of using a raw type here, it's possible to capture
// the wildcard but it will require a call to a supplementary
// private method
ListIterator fwd = list.listIterator();
ListIterator rev = list.listIterator(size);
for (int i=0, mid=list.size()>>1; i<mid; i++) {
Object tmp = fwd.next();
fwd.set(rev.previous());
rev.set(tmp);
}
}
}
public static void swap(List<?> list, int i, int j) {
// instead of using a raw type here, it's possible to capture
// the wildcard but it will require a call to a supplementary
// private method
final List l = list;
l.set(i, l.set(j, l.get(i)));
}
}
Java
복사
private List<ChatRes> queryChats(Long chatRoomId, Long lastChatId, int limitSize) {
QChat chat = QChat.chat;
QUser user = QUser.user;
BooleanExpression queryCondition = createQueryCondition(chat, chatRoomId, lastChatId);
List<ChatRes> chats = queryFactory
.select(Projections.constructor(
ChatRes.class,
chat.id,
user.id,
user.username,
user.profileImage,
chat.message,
chat.isDeleted,
chat.createdAt))
.from(chat)
.leftJoin(chat.sender, user)
.where(queryCondition)
.orderBy(chat.id.desc())
.limit(limitSize + 1)
.fetch();
Collections.reverse(chats); // <- ( 개선할 부분 )
return chats;
}
Java
복사
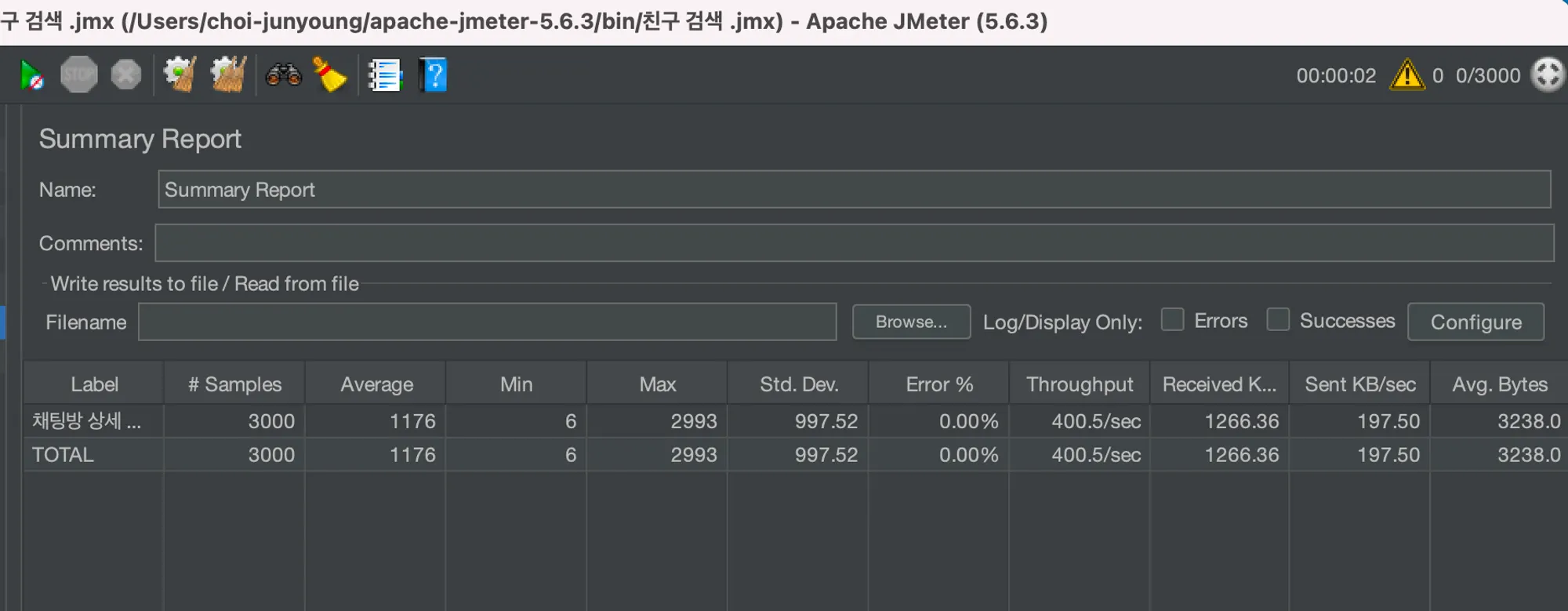
조회 데이터 (채팅의 개수) 2000개
평균 속도 1176ms
TPS(초당 데이터 처리량) 400.5/sec
Collections.reverse() X
Front에서 반환된 List 데이터를 역순으로 조회
private List<ChatRes> queryChats(Long chatRoomId, Long lastChatId, int limitSize) {
QChat chat = QChat.chat;
QUser user = QUser.user;
BooleanExpression queryCondition = createQueryCondition(chat, chatRoomId, lastChatId);
List<ChatRes> chats = queryFactory
.select(Projections.constructor(
ChatRes.class,
chat.id,
user.id,
user.username,
user.profileImage,
chat.message,
chat.isDeleted,
chat.createdAt))
.from(chat)
.leftJoin(chat.sender, user)
.where(queryCondition)
.orderBy(chat.id.desc())
.limit(limitSize + 1)
.fetch();
return chats;
}
Java
복사
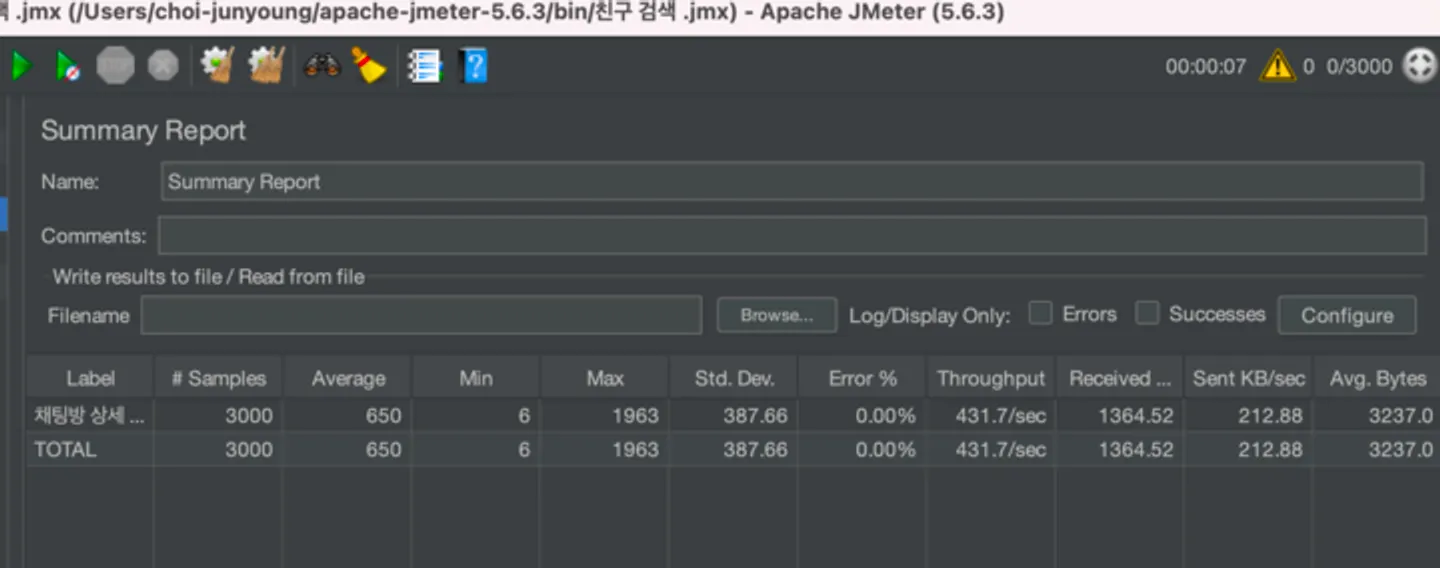
평균 속도 650ms
TPS(초당 데이터 처리량) 431.7/sec
결과
평균 속도 → 약 190% 성능 개선
TPS → 약 10% 성능 개선
