

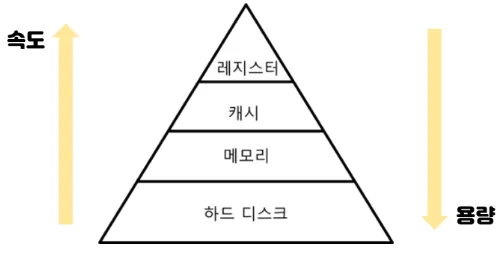
메모리 계층
•
컴퓨터의 메모리를 속도, 용량, 비용 등의 측면에서 여러 단계로 분류한 것을 의미한다.
•
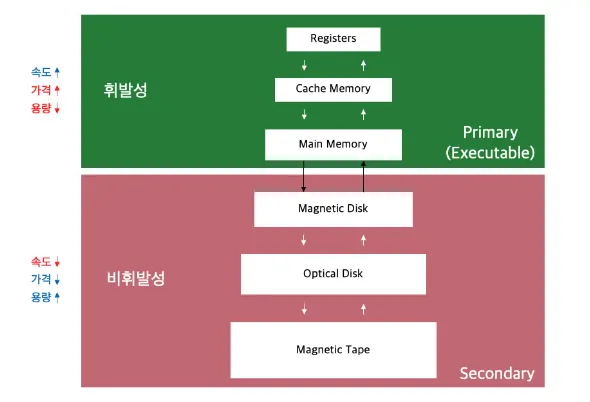
크게 레지스터, 캐시 메모리, 메인 메모리(주기억장치), 보조 메모리(보조기억장치)로 구성된다.
◦
레지스터
▪
CPU 내부에 위치해 있다.
▪
레지스터의 용량은 매우 제한적이지만, 그만큼 데이터에 대한 엑세스 속도가 빠르다.
◦
캐시 메모리
▪
레지스터와 메인 메모리 사이에 위치해 있으며, 높은 속도를 가지고 있다.
▪
자주 사용되는 데이터나 명령을 임시로 저장하는 역할을 한다.
▪
L1, L2, L3 등 여러 레벨로 구성되어있다.
▪
레벨은 메모리의 크기와 속도, 그리고 CPU와의 거리를 나타낸다.
(L1은 가장 빠르고 가까워서 용량이 작으며, L3는 가장 느리고 멀지만 용량이 크다.)
◦
메인 메모리 (주기억장치)
▪
일반적으로 RAM으로 알려져 있으며, 컴퓨터가 직접 접근할 수 있는 유일한 메모리이다.
▪
컴퓨터가 실행 중인 프로그램을 저장한다.
▪
컴퓨터가 켜져 있는 동안 프로그램에 필요한 데이터와 명령어를 저장한다.
▪
컴퓨터가 꺼지면 모든 데이터를 잃어버리는 휘발성 메모리이다.
◦
보조 메모리 (보조기억장치)
▪
하드 디스크, SSD 등이 이에 해당하며, 큰 용량을 가지고 있지만 접근 속도가 느리다.
▪
컴퓨터가 꺼져도 데이터가 지워지지 않는 특성을 가지고 있다.
•
메모리 계층의 필요성
◦
속도를 높이면 용량이 부족해지고, 용량을 높이면 속도가 느려지는 단점이 발생
◦
따라서 성능을 위해 속도와 용량의 상호보완을 위해 고안한 방법
◦
자주 쓰이는 데이터는 반복해서 쓰인다는 것을 참조 지역성이라고 한다.
즉 자주 쓰는 데이터는 계속 자주 쓰이고, 자주 쓰이지 않는 데이터는 계속 자주 쓰이지 않는다는 것이다. 따라서 자주 쓰일 것 같은 데이터는 메모리에 캐시로 읽어와, 메모리까지 가지 않고 한동안 캐시에서 해결이 가능하므로 시간을 단축시킬 수 있다. 자주 쓰이는 데이터는 전체 데이터 양에 비해 작은 양이기 때문에 캐시는 메모리보다 더 작아도 된다.
즉, 메모리 계층 구조의 아이디어는 프로세서가 필요로 하는 데이터를 최대한 가까운 곳에 위칫켜 속도를 향상시키는 것이다.
캐시
•
데이터를 미리 복사해 놓는 임시 저장소
•
빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리
•
속도 차이를 해결하기 위해 계층과 계층 사이에 있는 계층을 캐싱 계층이라고 한다.
•
지역성의 원리
◦
캐시를 직접 설정할 때는 지역성을 근거로 자주 사용하는 데이터를 기반하여 설정해야 한다.
•
시간 지역성
◦
시간 지역성은 최근 사용한 데이터가 가까운 미래에 다시 사용될 가능성이 높다는 개념
◦
이 원리를 이용하여 한번 참조된 데이터를 캐시에 저장해두면 다음에 같은 데이터를 참조할 때 바르게 접근할 수 있다.
public class TemporalLocality {
public static void main(String[] args) {
int[] arr = new int[100];
// 시간 지역성을 보여주는 예시
// 같은 위치의 데이터를 반복적으로 참조
for (int i = 0; i < 10000; i++) {
arr[0] = i;
System.out.println(arr[0]);
}
}
}
Java
복사
•
공간 지역성
◦
공간 지역성은 한 메모리의 위치를 참조하면 그 근처의 위치도 곧 참조될 가능성이 높다는 개념
◦
이 원리를 이용하여 데이터를 참조할 때 그 주변의 데이터도 함께 캐시에 저장해두면 근처의 데이터를 참조할 때 빠르게 접근할 수 있다.
public class SpatialLocality {
public static void main(String[] args) {
int[] arr = new int[100];
// 공간 지역성을 보여주는 예시
// 인접한 위치의 데이터를 순차적으로 참조
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
System.out.println(arr[i]);
}
}
}
Java
복사
캐시히트와 캐시미스
•
캐시히트
◦
CPU가 데이터를 찾을 때 캐시 메모리에 해당 데이터가 존재하는 경우
◦
이 경우, CPU는 빠르게 데이터에 접근할 수 있다.
•
캐시 미스
◦
CPU가 데이터를 찾을 때 캐시 메모리에 해당 데이터가 존재하지 않는 경우
◦
이 경우, CPU는 더 느린 메인 메모리로부터 데이터를 가져와야 한다.
캐시 매핑
•
캐시 메모리는 메인 메모리의 일부를 복사해 저장하기 때문에 메인 메모리의 어떤 부분이 캐시 메모리에 저장되어 있는지를 추적해야 한다. 이를 위해 캐시 매핑이 사용된다.
•
캐시 매핑에는 크게 직접 매핑, 연관 매핑, 그리고 집합 연관 매핑이 있다.
•
직접 매핑 (Direct Mapping)
◦
메인 메모리의 각 블록을 캐시 메모리의 한정된 위치에만 저장할 수 있는 방식
◦
매핑이 간단하다는 장점이 존재, 캐시 충돌이 발생할 확률이 높다는 단점이 있다.
캐시 충돌?

•
연관 매핑 (Associative Mapping)
◦
순서를 일치시키지 않고 관련 있는 캐시와 메모리를 매핑한다.
◦
충돌이 적지만 모든 블록을 탐색해야 해서 속도가 느리다.
•
집합 연관 매핑 (Set Associative Mapping)
◦
직접 매핑과 연관 매핑의 중간 형태로, 캐시를 여러 세트로 나눈 후 각 세트 내에서는 연관 매핑을 사용하는 방식.
◦
직접 매핑의 단순홤과 연관 매핑의 유연성을 동시에 얻을 수 있다는 장점이 있다.
웹 브라우저의 캐시
•
웹 브라우저에도 캐시 기능을 사용하여 최근 방분한 웹 페이지의 데이터를 저장하고, 재방문 시 빠르게 로드할 수 있도록 한다.
•
쿠키, 로컬 스토리지, 세션 스토리지 등 다양한 형태로 존재한다.
•
쿠키
◦
웹 사이트가 사용자의 브라우저에 저장하는 작은 텍스트 파일
◦
사용자의 웹 사이트 이용 정보를 저장하여, 사용자가 사이트를 재방문할 때 같은 설정을 유지하도록 한다.
•
로컬 스토리지
◦
웹 페이지의 데이터를 사용자의 컴퓨터에 영구적으로 저장하는 방법
◦
쿠키와 비교하여 용량이 크고, 서버로 자동 전송되지 않아 보안성이 높다.
◦
사용자의 설정, 사이트의 상태 등을 저장하고 유지하는데 사용
•
세션 스토리지
◦
로컬 스토리지와 비슷하지만, 브라우저 세션이 종료되면 데이터가 삭제되는 특징이 존재
◦
사용자가 사이트를 이용하는 동안 일시적으로 필요한 데이터를 저장하는 데 사용된다.
